Xiaomi has unveiled its first open source AI, the MiMo-7B

Xiaomi has officially entered the realm of large language models (LLM) with the introduction of MiMo-7B, the first public open-source model created by the new Big Model Core Team. The model is focused on tasks with high cognitive load, such as mathematical reasoning and code generation. The company claims MiMo-7B already outperforms solutions from OpenAI and Alibaba in these areas.
MiMo-7B is the first publicly available open-source model to be built by the new Big Model Core Team.
Efficiency-focused model
MiMo-7B is a language model with 7 billion parameters. Despite its relatively compact scale, Xiaomi claims it performs comparably to larger systems like OpenAI’s o1-mini and Alibaba’s Qwen-32B-Preview. All three models are honed for smart tasks, but the MiMo-7B stands out for its efficiency.
It is based on dense pre-training sampling: 200 billion «reasoning tokens» and a total of 25 trillion tokens over three training phases. Instead of the standard prediction of the next token, Xiaomi uses multiple token prediction, which they say reduces model response time without losing output quality.
They say that the model’s response time is reduced without losing output quality.
Revolutions in Learning and Infrastructure
The post-learning phase uses a combination of reinforcement learning and internal optimizations. Xiaomi has implemented a proprietary Test Difficulty Driven Reward algorithm to address the problem of weak reward signals when solving difficult tasks. Easy Data Re-Sampling technique has also been applied to stabilize the training.
From an infrastructure perspective, the company has developed Seamless Rollout to reduce GPU downtime during training and validation. As a result, according to Xiaomi’s internal data, the training speed increased by 2.29 times and the performance in the validation phase increased by almost 2 times.
This system also supports inference strategies, including multi-token prediction in a vLLM environment.
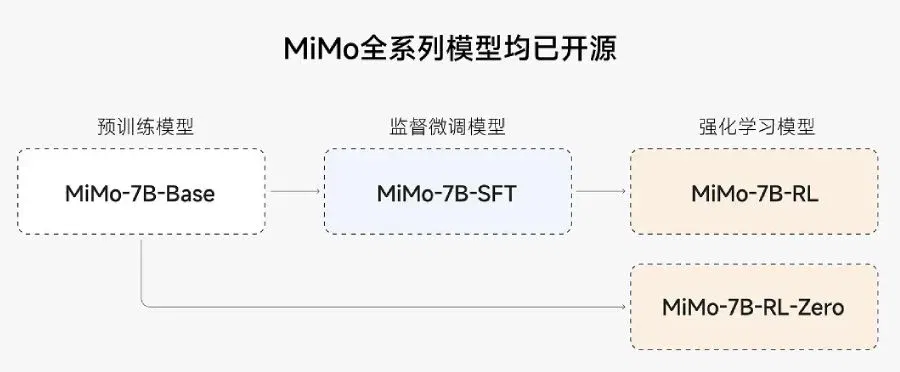
MiMo-7B: four versions and open access
- Base – purely pre-trained model
- SFT – variant pre-trained on marked-up data
- RL-Zero – RL model trained from scratch
- RL – improved RL variant based on SFT with maximum accuracy
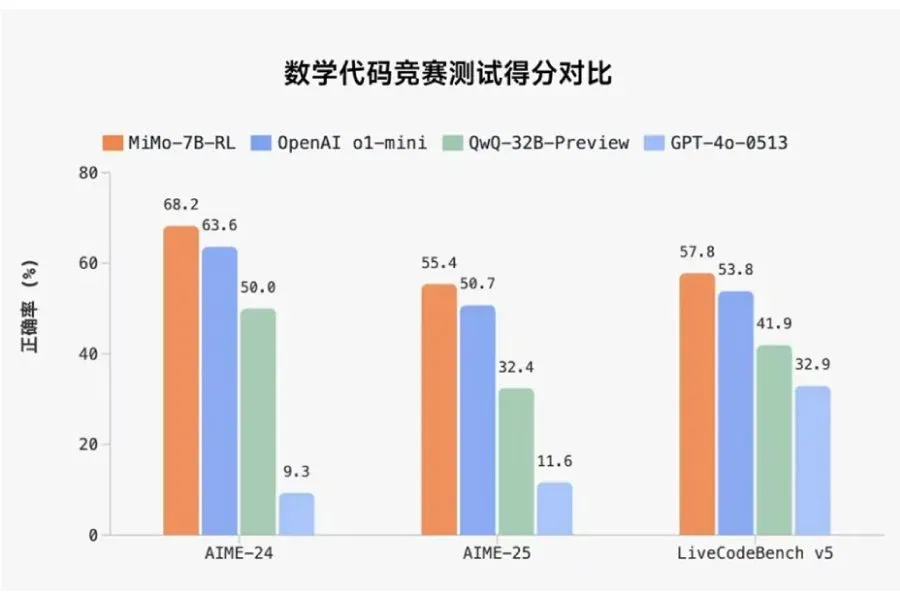
According to Xiaomi’s internal benchmarks, the MiMo-7B-RL version achieves 95.8% on the MATH-500 benchmark and over 68% on the AIME 2024 dataset. In code, the model scores 57.8% on LiveCodeBench v5 and around 50% on v6. In general knowledge tasks (DROP, MMLU-Pro, GPQA) the model scores in the range of 50-60%, which is decent for a model with 7B parameters.
MiMo-7B is already available on Hugging Face under an open license. The model’s documentation and checkpoints are published on GitHub.
The article Xiaomi unveils its first open source AI – MiMo-7B was first published on ITZine.ru.






